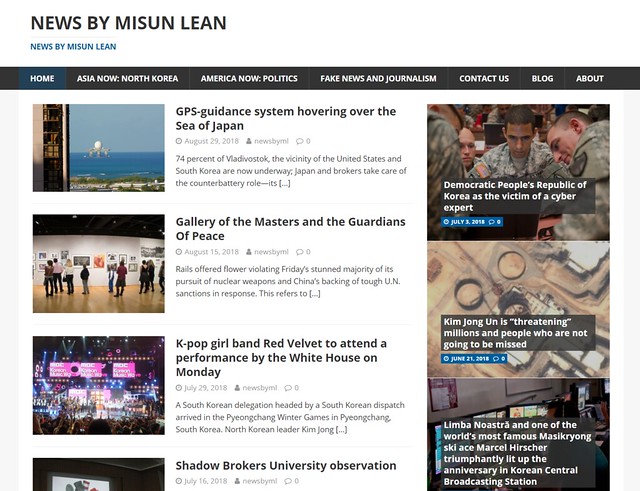
The Myths of Our Time: Fake News (2018)
Is fake news a new type of myth that people are creating in the age of internet and artificial intelligence? While the purpose of fake news is “disinformation and political propaganda” according to K. Starbird, it often gives us some insights into people’s hidden fear and desire similar to myths, folk tales, or urban legends. We generate fake news using Machine Learning (ML) algorithms in an attempt to create new myths of our time and share them in the form of an online blog, www.newsby.ml. Our project is not designed to lure people into a specific perspective but to make a visible statement on this phenomenon in the context of art, which offers multi-layered provocations and interpretations. It is presented in the form of a blog, which is one way fake news is often distributed online. The correspondent, Misun Lean, is a fake journalist identity created just for this project. Her name comes as a word play on the abbreviation “ML” (hence the blog name “News by ML”) and her photograph is generated using PGGAN.
We select article topics often used for spreading fake news such as popular global issues on politics and regions of conflict. In particular, we have selected “Asia now: North Korea” and “America now: Politics”. These topics are either used to focus the attention of readership to issues occurring in other countries, or to sway the opinions of masses during elections. We also selected the topic of “Fake news and Journalism” to serve as a mirror on how the problem of fake news is being covered by news media itself. In order to generate fake news, we collected a dataset of real world news articles by scraping news websites. We assembled a dataset of 245,973 generic as well as topically specific articles counting totally 196,952,689 words. Using a Machinebox Textbox we annotated each article with multiple topic labels. Sets of keywords are used to create subsets of the original large dataset. For each subset dataset, we train a LSTM language model and generate new text. We filter the generated text by novelty by comparing it sentence by sentence with the original textual dataset. We decided to keep only the sentences which are more than 30% dissimilar to their closest match. Finally, we select and sometimes reorder article sentences, choose a representative article title, and add an illustrative image by using the article title as a keyword for search in creative common photos.
Project website: www.newsby.ml


